
When we try to replicate the real-world thinking or mimic the human thought process in any form or shape, it’s important to recognize that the world itself is inherently relational. Humans understand, react, and make decisions by connecting all these — people, emotions, experiences, and contexts. Then why are we forcing to compress all this richness into vectors, thus effectively stripping away the relational semantics that give problems their real meaning?
When we use the vector DB for storing, we are losing the relationships. In Vector DB, each piece of data is converted into a vector embedding a long list of numbers, and these numbers will be saved in the vector database. When you search for something, it uses a similarity search algorithm like cosine similarity, Euclidean distance, etc, to find the most similar vectors. This is ideal for simple question-answer models, recommendation systems, etc, where we do Single-hop queries or similarity search or try to retrieve stats.
But what will you do when you can’t compromise on accuracy and speed, and it is non-negotiable?
This is where the Knowledge Graph or Graph RAG comes in handy. This can do multi-hop travles and each hop can have weightage. In a knowledge graph, the data is stored as facts, entities, and relationships. Where each entry represents explicit knowledge, and relationships between entities are explicitly defined.
This is why this is useful in tasks where reasoning & inference, precision & accuracy, ontology & the relationships matter the most.
The simple difference between Vector RAG and Graph RAG is as below:

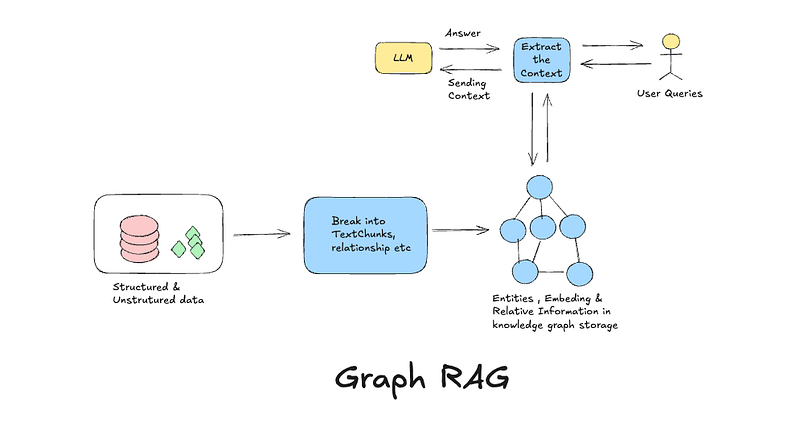

This does
This doesn’t mean you can’t interchange these. Instead, it’s better to match your data structure to your reasoning requirements, not your technology preferences.
In practice, its better to use a hybrid architecture combining vector, graph, and relational databases to leverage the strengths of each. This approach allows you to retrieve both meaningful (semantic) and precise (factual) information, especially when integrated with an LLM.
